NVIDIA发布预训练模型工具包 看TLT 3.0如何简化AI构建流程
日前,一年一度的全球计算机视觉顶级会议 CVPR(Conference on Computer Vision and Pattern Recognition)落下帷幕。NVIDIA在会议期间发布全新预训练模型,并宣布迁移学习工具包(TLT)3.0全面公开可用。
据了解,在新版本中包括高精度和高性能计算机视觉和对话式AI预训练模型,此外,还有一套强大的生产级功能,可以将AI开发的能力提升10倍。
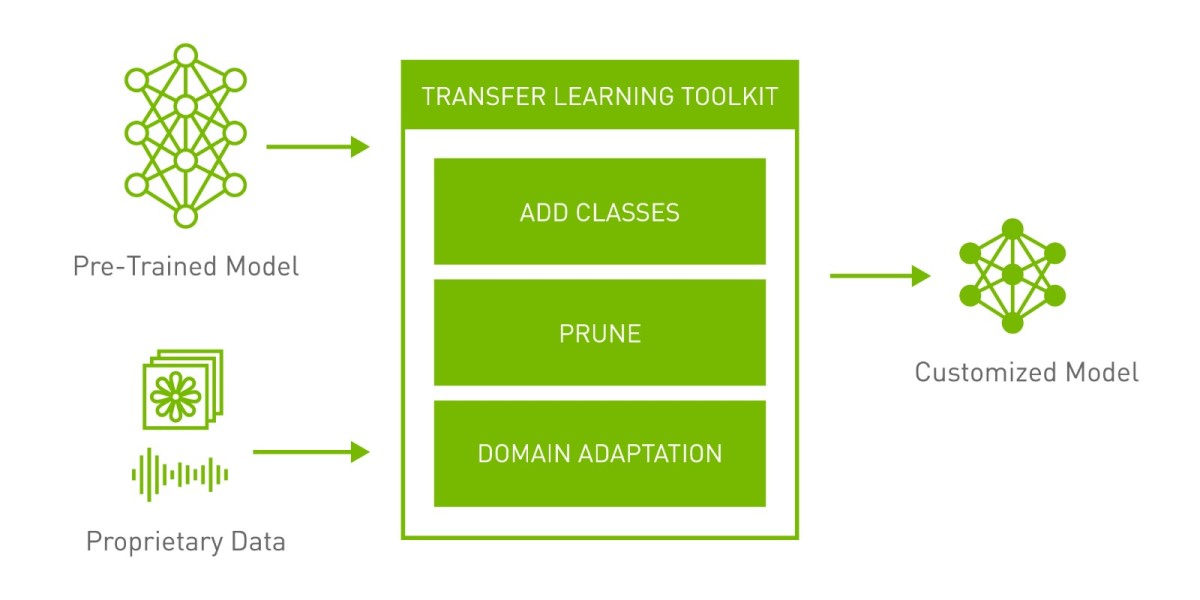
TLT 3.0简化AI构建流程
在我们谈论TLT 3.0之前,先来看一看TAO框架架构,为什么要看这个架构呢?因为TAO的核心组成,就包括预训练模型本身、TLT――迁移学习工具包、联邦学习,还有TensorRT、Fleet Command这样的组成部分。
今年早些时候的GTC上,NVIDIA宣布的TAO时,提到“可针对NVIDIA AI预训练模型进行微调和适配”。另外,对TAO的定义有更大的外延,TAO是个“平台”,通过基于UI的、引导式的工作流,简化AI应用的构建过程,针对不同能力水平的AI专家来满足不同的需求。
借助NVIDIA Tao框架,能让多方研究人员训练共享的模型,又同时能够确保资料隐私不会受到恶意侵犯。NVIDIA Tao框架也能通过剪枝(Pruning)与量化(Quantization)等优化方式在不影响准确度的前提下,降低运算复杂度与模型尺寸,节省占用的计算资源并提升性能表现。
所以,我们可以了解到,TLT是TAO的一个核心组成部分。因此,企业可以在不需要太多大数据、AI专家的情况下去做AI,应用可能包括人、车、各种对象的识别、对话AI等。
如何实现迁移,需要首先获得精确度比较高的预训练模型,利用TLT基于自身数据集进行模型优化,这样模型就能部署到应用中了。此后,NVIDIA可以用DeepStream等视频流分析SDK工具,或者Jarvis等对话式AI,来做模型的部署,从而实现整体解决方案。
我们发现,NVIDIA提供高质量的预训练模型和TLT可以帮助降低大规模数据采集和标注成本,同时告别从头开始训练AI/机器学习模型的负担。初入计算机视觉和语音服务市场的企业现在也可以在不具备大规模AI开发团队的情况下部署生产级AI。
TLT新版本亮点包括:推理性能比OpenPose模型快9倍的支持边缘实时推理的姿态估计模型;用于人物检测的语义分割网络;各种行业用例中的计算机视觉预训练模型;AWS、GCP和Azure上的训练支持等。
另外,NVIDIA表示,TLT 3.0现在还与数家领先合作伙伴的平台集成,这些合作伙伴提供大量多样化的高质量标签数据,使端到端AI/机器学习工作流程变得更快。
AI由算力支配
目前,NVIDIA已经在人工智能芯片领域占据了主导地位,过去的数年间,在亚马逊云服务(AWS)、谷歌、阿里巴巴和微软Azure这四大云服务商的数据中心中,97.4%的人工智能加速器中部署的都是英伟达GPU芯片,而在全世界500强超级计算机中,近70%使用的也是英伟达GPU。
同样在CVPR 2021上,汽车制造商特斯拉的AI高级总监Andrej Karpathy公布了公司内部用于训练Autopilot与自动驾驶深度神经网络的超级计算机。这个集群使用了720个节点的8个NVIDIA A100 Tensor Core GPU(共5760个GPU),实现了1.8 exaflops级别的超强性能。
特斯拉这台超级计算机上面搭载的NVIDIA A100 GPU为全球最强的数据中心提供各种尺度的加速。A100 GPU基于NVIDIA Ampere架构打造,其性能比上一代产品高出20倍,并且可以划分成7个GPU实例,动态地适配不同的需求。
据悉,特斯拉的数据循环始于汽车。“影子模式”在不实际控制车辆的情况下,悄无声息地执行着感知和预测深度神经网络(DNN)。据了解,DNN需要庞大的计算能力,因此,特斯拉为DNN建立并部署了内置高性能A100 GPU的最新一代超级计算机。
另外,吴恩达的YouTube视频猫识别系统、DeepMind开发的围棋冠军AlphaGo、OpenAI的语言预测模型GPT-3都是在英伟达的硬件上运行。
写在最后
未来,人工智能会将触角延伸到我们生活、工作中的每一处角落,就像万物互联的浪潮。而现在,NVIDIA已经率先出发,并将引领各行各业进入到更加迷人的人工智能时代。

 X
X

-
 微博认证登录
微博认证登录
-
 QQ账号登录
QQ账号登录
-
 微信账号登录
微信账号登录

企业俱乐部
Copyright (C) 1997-2025 Chinabyte.com, All Rights Reserved
